Redis
Cache
캐시란 나중에 요청할 request에 대한 response를 미리 저장해두는 곳으로 DB또는 API를 참조하지 않고 빠른 응답이 가능하게 해준다.
캐시의 등장 배경
“80%의 결과는 20%의 원인에 의해 발생한다”라는
파레토 법칙으로부터 캐시라는 개념이 등장했다. → 서비스에서 자주 사용되는 20%의 데이터를 캐시에 저장하므로써 전체적인 효율을 끌어올릴 수 있다.사용자가 늘어나 DB에 요청이 몰리면서 디스크 IO가 자주 발생한다. 이는 결국 성능을 떨어뜨리기 때문에 DB Scaling Out, Scaling Up 또는 캐시를 사용하는 것을 검토해봐야 한다.
캐싱 과정
클라이언트가 서버에게 request를 보낸다
서버는 request에 해당하는 데이터가 캐시에 존재하는지 확인한다.
존재한다면(cache hit) 바로 응답한다
존재하지 않다면(cache miss) DB나 서버에서 데이터를 조회한 뒤 응답한다
캐시 사용 방식
Look Aside Cache(Lazy Loading) → 대부분의 캐시는 이와 같은 프로세스로 구성된다
클라이언트가 서버에게 request를 보낸다
서버는 캐시에 데이터가 존재하는지 확인한다
캐시에 데이터가 있다면 해당 데이터를 반환한다
없다면 DB에서 조회한 후 반환한다.
Write Back → 쓰기 작업이 많은 서비스(배치 작업)에서 사용되는 구조이다
서버는 모든 데이터를 캐시에만 저장한다
일정 주기마다 캐시에 있는 데이터를 DB에 저장한다
DB에 저장된 데이터를 캐시에서 제거한다
온라인 테스트 서비스에서 여러 사용자가 “제출” 버튼을 누를 때, DB에 바로 insert한다면 요청이 몰려 DB 서버가 죽을 수 있다. 이 경우 Write Back 기법을 사용하여 DB에 안전하게 데이터를 저장할 수 있다
Memcached
Memcached란 오픈 소스 분산 메모리 캐싱 시스템으로 사용하지 않는 서버를 활용한 것이다.
consistent hash 알고리즘을 사용하여 물리적인 별도의 캐시 서버를 로직상의 하나의 서버로 간주하여 사용할 수 있도록 한다. → 여러 서버에서 하나의 캐시 서버에 데이터를 저장, 조회할 수 있다.
오래된 저사양 서버의 잉여 메모리를 활용한다.
Memcached의 단점
인메모리 시스템이기 때문에 캐시 서버를 재부팅할 경우 데이터가 휘발된다. 즉, Memcached 시스템을 영구 저장 시스템으로 활용하기에 적합하지 않다.
데이터를 영구적으로 저장하려면 비휘발성 저장소에 저장해두고, 캐시 서버를 재부팅할 때 데이터를 캐시 서버로 적재해야 한다.
Redis
Redis(Remote Dictionary Server)란 외부에서 사용할 수 있는 인메모리 NoSQL 데이터베이스이다.
Redis는 고성능 키-값 저장소로서 String, Bitmap, Hash, List, Set, Sorted Set 등의 다양한 자료 구조를 저장할 수 있는 NoSQL 데이터베이스이다.
Redis에서 저장하는 데이터
key-value 쌍의 데이터를 key로 조회할 수 있기 때문에 조회 속도가 매우 빠르다 → O(1)
문자열부터 JPEG 파일까지 모든 이진 시퀀스를 key로 사용할 수 있다. key는 최대 521MB이다.
인메모리 데이터베이스?
disk가 아니라 메모리에 데이터를 저장하는 데이터베이스이다. 그렇기 때문에 저장할 수 있는 데이터의 양이 제한적이다.
Redis의 용도
조회수 카운트 형태의 데이터: IO작업이 빈번하게 발생하여 Redis가 아닌 다른 저장방식을 사용하면 비효율적인 경우에 Redis를 사용한다사용자 세션 관리: 사용자의 세션을 유지하려는 용도로 사용된다인증 토큰 저장용: Refresh Token 저장용API 요청 결과 캐싱용
Redis의 특징
🧩 영속성을 지원하는 인메모리 데이터 저장소이다 : RDB, AOF 방식
🧩 영속성을 지원하는 인메모리 데이터 저장소이다 : RDB, AOF 방식Redis는 데이터의 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있다.
Redis 서버가 재부팅되어 데이터가 휘발되어도 디스크에 저장된 데이터를 로드한다
다만 데이터를 항상 정확하게 유지되진 않는다.
Redis의 데이터를 디스크에 저장하는 방식에 2가지가 존재한다. (참고)
RDB(Snapshotting) 방식: 한 순간에 메모리 속 데이터 전체를 바이너리 파일(.rdb)로 저장하는 방식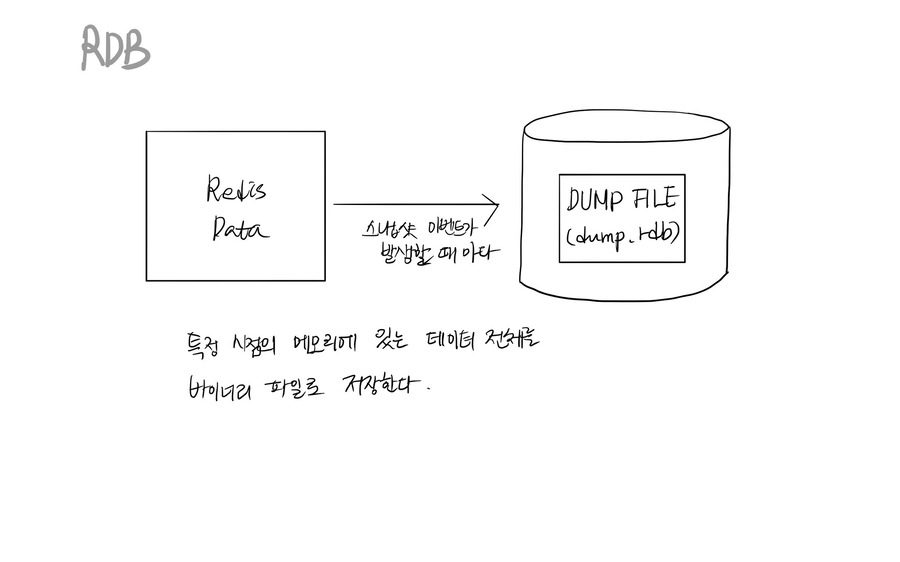
장점
메모리의 스냅샷을 파일로 저장하기 때문에 Redis 서버를 재부팅할 경우 해당 파일만 불러 오면 된다
바이너리 파일(.rdb)은 AOF 파일(텍스트)보다 사이즈가 작기 때문에 로딩 속도가 비교적 빠르다
단점
메모리 스냅샷을 파일로 추출하는 시간이 오래걸린다. 추출 중간에 장애가 발생하면 마지막 스냅샷 이후의 데이터를 모두 잃을 수 있다.
AOF(Append On File) 방식: Redis의 모든 write, update 연산 자체를 log 파일(.aof)에 기록하는 방식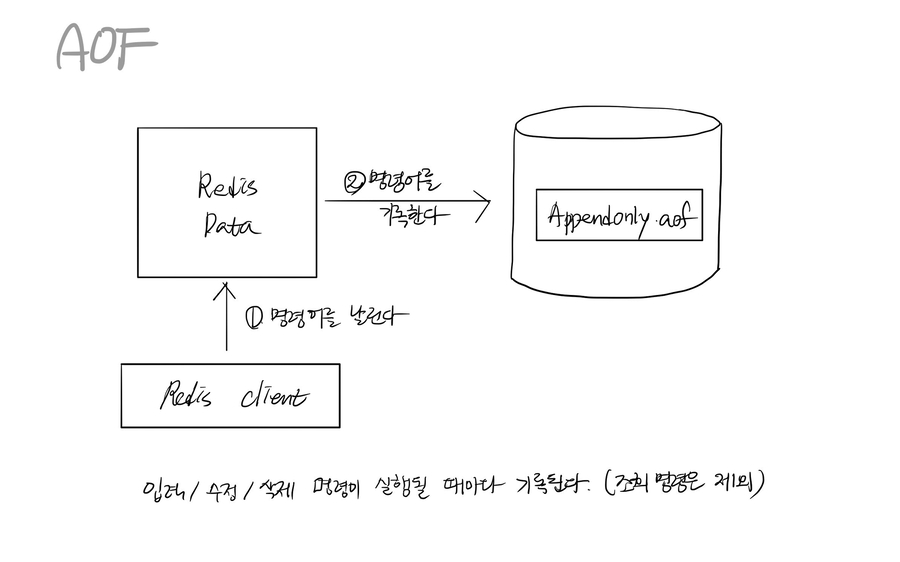
장점
데이터 유실이 발생하지 않는다
단점
RDB 방식에 비해 더 많은 디스크 용량을 차지한다
log 파일에 기록된 모든 명령어를 실행시키기 때문에 재부팅 시 응답시간이 오래 걸린다.
스냅샷과 AOF방식을 혼합해 사용하는 것이 권장된다.
RDB → 주기적으로 메모리 스냅샷을 찍어 .rdb 파일에 저장한다
AOF → 다음 스냅샷까지의 log를 AOF 방식으로 저장한다.
서버 재부팅시 .rdb 파일을 불러오고 비교적 적은 양의 AOF 로그만 재실행해준다
🧩 다양한 자료구조를 지원한다
🧩 다양한 자료구조를 지원한다Redis는 다양한 자료구조를 지원하여 개발 편의성을 제공한다. 이 특징은 다른 인메모리 데이터베이스와 큰 차이점이다.
Redis와 Memcached의 차이점 : 지원하는 자료구조의 다양성
🧩 빠르다
🧩 빠르다Redis는 disk에 접근하지 않고 메모리에 접근하여 데이터를 가져오기 때문에 속도가 빠르다.
Redis의 성능은 Memcached에 버금가면서도 다양한 데이터 구조체를 지원하기 때문에 DB, Cache, Message Queue, Shared Memory 용도로 사용될 수 있다.
🧩 싱글 스레드 방식으로 연산을 원자적으로 수행한다
🧩 싱글 스레드 방식으로 연산을 원자적으로 수행한다Redis는 싱글 스레드를 사용하기 때문에 연산을 원자적으로 처리한다. 다시 말해, Race Condition이 거의 발생하지 않는다. (Thread Safe하다)
Redis에서 제공하는 자료구조 (참고)
String
가장 일반적인 형태의 자료구조
- key → string
- string 타입에 이진 데이터를 포함한 모든 종류의 문자열을 저장할 수 있다. (JPEG, HTML)
- 레디스의 키가 문자열이므로 이 구조는 문자열을 다른 문자열에 매핑하는 것
List
LinkedList 특징을 가진 자료구조
- key → 여러 list 원소
- list 내에 수백만 개의 아이템이 있더라도 head와 tail에 값을 추가할 때 동일한 시간이 소요된다.
- Pub-Sub 패턴 : 생산자가 데이터를 만들어 list에 넣으면 소비자가 list에서 데이터를 꺼내 액션을 수행한다
- 트위터에서는 각 유저의 타임라인을 보여주기 위해 Redis의 list를 사용한다
Hash
field-value 쌍의 일반적인 해시 자료구조
- key → 여러 fleld-value 쌍의 데이터
- key에 대한 field 개수에 제한이 없다
- RDB의 테이블과 비슷하다 (hash key는 table의 PK, field는 column, value는 value)
Set
set은 정렬되지 않고 중복되지 않는 문자열의 모음
- key → 순서가 없고 중복되지 않는 여러 데이터
- 객체 간의 관계를 표현할 때 좋다
- 교집합, 합집합, 차집합 연산을 수행할 수 있다
Sorted Set
정렬되고 중복되지 않는 문자열의 모음
- key → 중복되지 않는 member-score 쌍의 여러 데이터
- 저장되는 데이터는 score를 기준으로 정렬된다. (score값이 동일하다면 member의 사전 순서로 정렬)
- 데이터가 정렬되어있기 때문에 인덱스로 빠른 조회가 가능
주의 사항
🧩 메모리 관리가 매우 중요하다
🧩 메모리 관리가 매우 중요하다Redis는 데이터를 메모리에 저장하기 때문에 메모리 관리가 필요하다.
메모리 파편화 문제: 다양한 사이즈의 데이터를 저장하기 때문에 메모리 파편화 문제가 발생할 수 있다. → 가급적 비슷한 사이즈의 데이터를 저장하는게 바람직하다swapping으로 인한 속도 저하: 가용 메모리보다 큰 데이터를 저장한다면 swapping이 발생한다. 사이즈가 큰 데이터에 접근한다면 page swap in, out이 발생하여 검색 속도에 영향이 미친다.
🧩 저장 공간이 한정적이다
🧩 저장 공간이 한정적이다Redis는 데이터를 메모리라는 한정적인 공간에 저장한다.
메모리가 가득찬 경우 가장 먼저 들어온 데이터를 삭제하거나, 가장 최근에 사용되지 않는 데이터를 삭제하거나, 데이터를 입력받지 못할 수 있다.
저장 공간이 가득찬 경우 사용자가 직접 삭제될 데이터 기준을 설정하는게 바람직하다 → 데이터의 사용 기한
Expire를 설정하여 key에 대한 timeout(만료 시간)을 지정해준다. 만료 시간이 경과하면 key가 자동으로 삭제된다.Expire는 Collection의 item 별로 설정할 수 없고 Collection 전체에 설정된다. → Collection 내부의 모든 item이 삭제된다
🧩 O(N) 관련 명령어는 피하자
🧩 O(N) 관련 명령어는 피하자Redis는 싱글 스레드 방식으로 연산을 수행한다. 따라서 요청 처리 시간이 오래 걸리면 뒤에 오는 나머지 요청들은 계속 대기해야 한다.
하나의 요청이 1초 소요된다면 나머지 9999개의 요청은 모두 1초동안 대기해야 한다. 최악의 경우 뒷단의 요청에 TIME_OUT이 발생하여 서비스가 터질 수 있다.
따라서 처리 시간이 O(N)인 명령어를 피하는게 좋다. (KEYS, FLUSHALL, FLUSHDB, Delete Collection, Get All Collections)
Last updated